A while back I wrote about sucatisse, my project for turning decades-old car workshop manuals into clickable, searchable, mobile-friendly things. The extraction half of that pipeline runs on cloud Claude (Opus), one batch request per page, and the structured JSON it spits out is what the site is built from.
It works well. But every page costs tokens, and every page needs a network round-trip. So I spent a day on a different question. My MacBook is an M5 Pro with 48 GB of unified memory. Can it just do the whole thing itself, with no network and no per-token cost, and how close does it get to the Claude output that already ships in the S13 data?
To find out I built macOS-local: a self-contained pipeline that rasterizes each page, runs layout detection, hands the page to a vision model for extraction, and crops the figures. Then I iterated on the extraction stage twice, because the first idea didn’t survive contact with reality.
The setup
Everything runs on MLX, Apple’s native inference stack, via mlx-vlm. Layout detection is Surya, which I had to keep in its own isolated venv because it needs transformers<5 and mlx-vlm needs ≥5.5, and they refuse to live in the same environment. Rasterizing is PyMuPDF at 300 dpi grayscale. The reference I’m grading against is the shipped Claude extraction: 881 pages, mostly claude-opus-4-7.
One thing about local inference on this hardware: reading a page is memory-bandwidth-bound. Every token the model generates reads the entire model out of unified memory, so the model size and the quantization level set your speed, and a single GPU means you can’t run two models side by side for free. That constraint shaped both attempts.
Attempt one: the ensemble
My first idea was an inverted version of how you’d normally tier models in the cloud. Run cheap models on every page, and only pay for the expensive one where the cheap ones disagree. Two 8B vision models (Qwen3-VL-8B and InternVL3-8B, both 4-bit) read each page and vote. A judge reconciles them. If they don’t agree well enough, the page escalates to a 30B mixture-of-experts model.
That was the plan. Here’s what running it actually looked like:
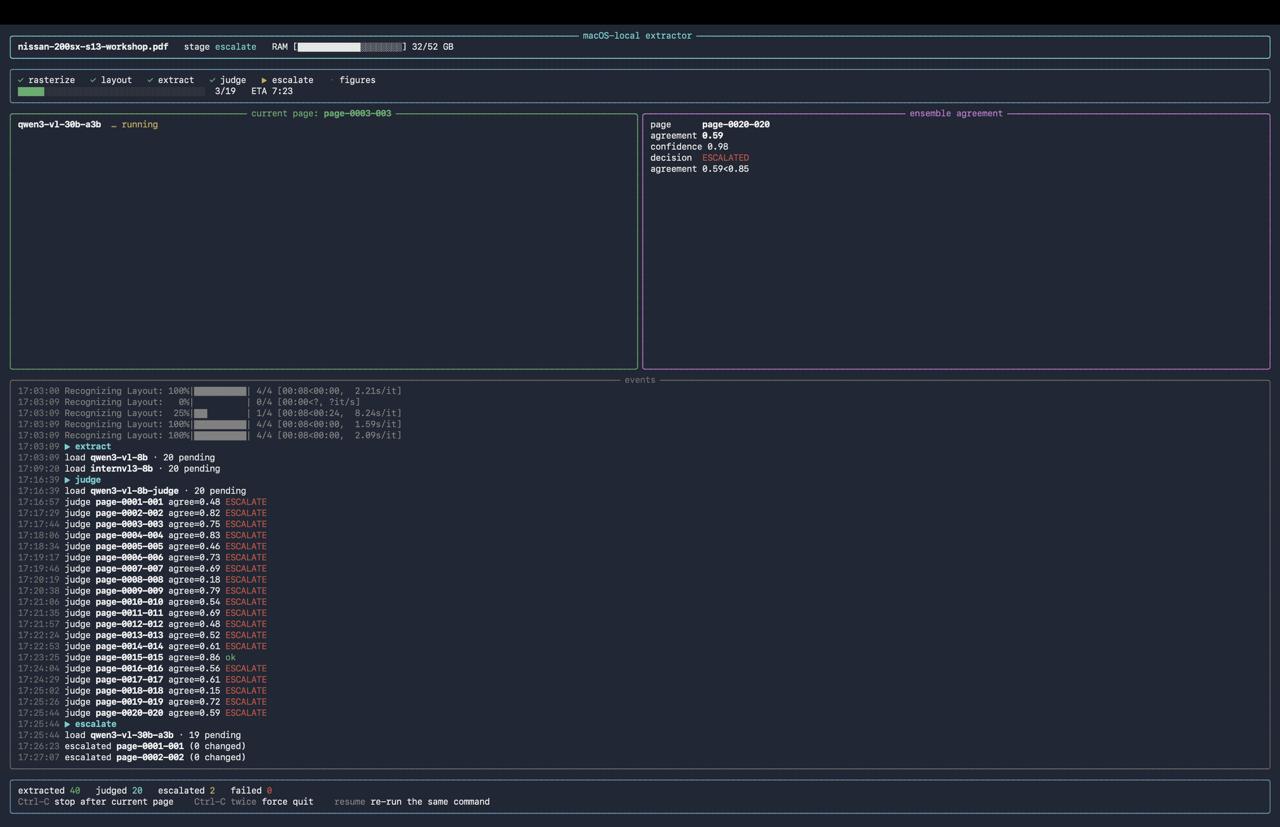
Look at the agreement column. The plan was that most pages would clear the cheap path and stop. Instead the two 8B models structured pages so differently that mean agreement landed at 0.60, well under my threshold, so 19 of 20 pages escalated anyway. The cheap path almost never terminated. I was paying for the entire stack on nearly every page, which is exactly the thing the design was supposed to avoid. On top of that, 4-bit quantization seemed to be hurting digit reading.
The scores against Claude told the same story. Here’s the ensemble on 20 pages:
| metric | ensemble vs Claude |
|---|---|
| numeric recall | 0.61 |
| table-cell recall | 0.17 |
| block-structure recall | 0.52 |
| text recall / precision | 0.73 / 0.96 |
| page-type match | 60% |
Text coverage was fine and it wasn’t hallucinating (0.96 precision), but it missed about 40% of the numbers and barely reproduced tables at all. On the table-of-contents page it flattened the entire section-code index into 22 plain headings and lost every code. For a workshop manual, where the numbers are the content, that’s a fail.
Attempt two: one big model, twice
So I threw the ensemble out and did the opposite. Instead of several small models voting, use the single biggest, highest-precision model the 48 GB box can hold, and let it check its own work.
That meant Qwen3-VL-32B-Instruct at 8-bit, which is about 36 GB and fits with not much room to spare. I went 8-bit rather than 4-bit specifically to fix the digit problem from attempt one. I fed it the page at 2048 px instead of 1536 so small numbers stay legible, ran two passes (the second pass re-reads the page plus the first draft and is told to fill in anything missed), and hardened the schema so malformed blocks stopped blowing up the run.
On easy pages, it basically matches Claude
On the two front-matter pages I’d compared head-to-head with the ensemble, the solo model jumped on every axis:
| metric (front-matter pages) | ensemble | solo |
|---|---|---|
| numeric recall | 0.61 | 1.00 |
| table-cell recall | 0.00 | 1.00 |
| block-structure recall | 0.66 | 0.90 |
| text recall | 0.75 | 0.99 |
| page-type match | 1 / 2 | 2 / 2 |
It captured the table-of-contents section codes the ensemble had destroyed, and it recovered the cover title. On easy pages, this is Claude-parity.
On hard pages, the truth comes out
Front matter is the easy stuff. The real manual is spec tables, exploded parts diagrams, wire-level schematics, and diagnostic flowcharts. So I added a page selector and pointed it at 10 dense pages deep in the book, including a spec page with 316 numbers on it and an HVAC diagnostic table with 337.
Two of the ten turned out to be unusable: the local 881-page PDF and the Claude corpus drift apart around the foldout wiring pages, so those page numbers point at physically different pages with almost no text in common. Excluding those, here are the eight aligned dense pages, with the ensemble’s front-matter scores alongside for contrast:
| metric | solo (8 dense pages) | ensemble (front-matter) |
|---|---|---|
| numeric recall | 0.67 | 0.61 |
| table-cell recall | 0.56 | 0.17 |
| block-structure recall | 0.63 | 0.52 |
| text recall | 0.72 | 0.73 |
How well it does depends enormously on the page:
- Spec tables are great. One parts-data page scored 0.94 text, 0.95 numbers, and 0.96 table cells. The 316-number spec page hit 0.90 numeric recall.
- Diagrams and dense diagnostics are not. An exploded parts diagram collapsed into a single block. A wiring page managed 0.30 on numbers. That 337-number HVAC table came back at 0.17.
So the solo model fixed the ensemble’s structural collapse (tables went from 0.17 to 0.56) and nudged ahead on numbers. But the front-matter near-perfection does not carry over to dense content, where it still drops about a third of the numbers. Not Claude-parity on the hard pages, which are the pages that matter most.
The second pass earned nothing
Here’s the part I didn’t expect. Across all 12 solo pages, the verify pass added zero blocks. Whatever small value-level corrections it made (and I didn’t measure those), it recovered no missing content, while doubling the time. As built, the two-pass design isn’t paying for itself.
The wall I actually hit
There’s no dollar cost here, but there’s wall-clock, and it’s brutal:
| on the dense pages | value |
|---|---|
| avg per page (2 passes) | ~10.8 min |
| slowest single page (a wiring diagram) | ~24 min |
| 10 dense pages, total | ~107 min |
| front-matter pages (earlier) | ~2-3 min/page |
| peak RAM (no headroom to spare) | ~36 GB |
| extrapolated to the full 881-page manual | ~6 days |
The model sat at ~36 GB of RAM the whole time, with no out-of-memory crashes but no headroom either. Extrapolate the dense-page rate to the whole 881-page manual and you get roughly six days of continuous compute, three if you drop to a single pass. That settles it for bulk work. Doing a whole manual locally on one machine isn’t practical. Targeted pages, a small manual, an overnight batch: fine. The whole book on one box: no.
What I took away from it
A few things became clear by the end:
- One big 8-bit model beats a 4-bit ensemble for this. Better numbers, far better tables, a much simpler pipeline. The clever agreement-based escalation just collapsed in practice.
- Quantization precision matters for digits. Going from 4-bit to 8-bit was the single lever that moved numeric recall, which makes sense when the whole point is reading torque values off a photocopy.
- Local matches Claude on easy pages and trails on hard ones. Dense wiring, parts diagrams, and big diagnostic tables are where the gap lives.
- Throughput is the constraint, not quality or money. Eleven minutes a page doesn’t scale to a full book on one box.
- The verify pass, as designed, isn’t worth twice the time. It added nothing.
Where I’d take it next
The obvious move is to make pass two cheaper or drop it by default, and only re-verify pages that look uncertain. That’s the original escalation idea, except gated on the model’s own uncertainty rather than two models disagreeing. I want to chase the dense-page number gap with full-resolution input on spec pages, or a proper document-OCR specialist once one is turnkey on MLX. I’d like to try the 30B mixture-of-experts model at 8-bit as the primary, since it only activates ~3B parameters per token and should decode much faster. And I need to fix the page alignment between the local PDF and the Claude corpus before any larger comparison, because losing 2 of 10 deep pages to drift made them non-comparable.
For now Claude stays in the pipeline. But it’s genuinely close on the easy 80%, and the on-device version costs nothing and never touches the network, so I’m not done poking at it.
A caveat on the numbers: these are automated structural and text-overlap scores against the shipped Claude data, which isn’t ground truth itself, so they undercount output that’s semantically right but structured differently. The samples are small. The scanned page, not the Claude reference, is the real arbiter.