A while back I bought a Nissan 200sx. Naturally, the only proper repair info that exists is a 500-page workshop manual scanned out of a 1990s binder, full of grainy diagrams and torque tables that you navigate with Cmd+F and a lot of patience. So I started building the thing I wanted: a real, clickable, searchable, mobile-friendly version of that manual.
That side project grew an umbrella name, sucatisse (Portuguese-flavoured slang for “scrappy stuff”), and now hosts two manuals so far:
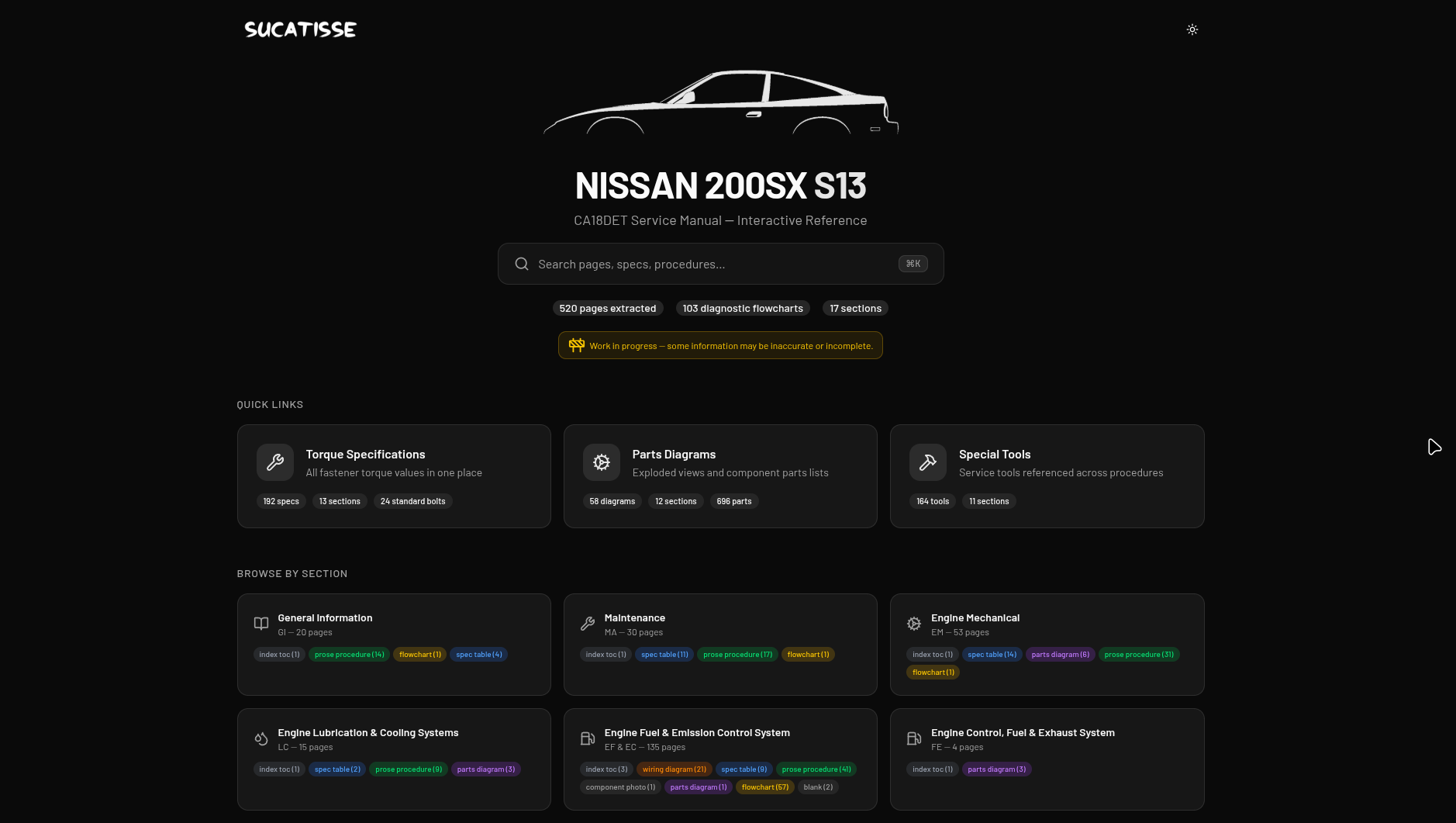
- s13.sucatisse.com: Nissan 200sx (S13)
- k11.sucatisse.com: Nissan K11
Same codebase, same pipeline, different car. This post is the first in what’ll probably be a small series. Here’s the high-level shape of how the sausage gets made.
The shape of the data
Workshop manuals look simple from across the room and get scary up close. Pages are dense, figure-heavy, and cross-referenced by code (FA-3 for Front Axle page 3, EM-12 for Engine Mechanical page 12, etc.). A typical page mixes a torque table, a numbered exploded diagram, a step-by-step procedure that points back at the diagram, and a fault-finding flowchart, all on one A4.
Pure OCR turns that into a wall of text and loses everything that made it useful. What I actually want is structured blocks: a procedure, a specs table, a flowchart, a parts_diagram, a wiring_schematic. Things the frontend can render as first-class UI instead of dumping back the original photocopy.
Which is exactly the kind of job Claude is good at.
The pipeline
The flow ended up being an iterative loop, not a one-shot batch:
- Annotate the PDF in a custom tool I built called human-touch (more on that in a sec). Mark cover/index/blank pages as ignore. Draw bounding boxes around figures so the extractor knows what to pull out as images. Drop notes on weird pages.
- Design the extraction with Claude Code. I’d point Claude Code at a small handful of representative pages and iterate on the prompt and the target JSON schema interactively. Claude Code is brilliant for this. It’s the fastest way I’ve found to converge on “the prompt that produces the JSON I actually want” without burning real money on bad batch jobs.
- Run the Anthropic batch API over the rest of the manual. Once the prompt is dialled in, batching is a no-brainer for this workload: ~50% cheaper per token, and throughput genuinely doesn’t matter when you’re queueing 500+ pages and going to bed. Each page becomes one batch request, output is one structured JSON file.
- Spot-check the output. Open the rendered manual, click through. Find the page where the model dropped a figure, mis-labelled a torque value, or hallucinated a step that wasn’t there.
- Loop back into human-touch. Tighten the figure box, leave a note for the extractor (“the spec table on this page has a footnote, include it”), and re-run just that page through the API. Repeat until the diff between runs stops being interesting.
Two things made this loop work in practice: Claude Code for the design phase, and human-touch for the correction phase.
human-touch: the missing piece
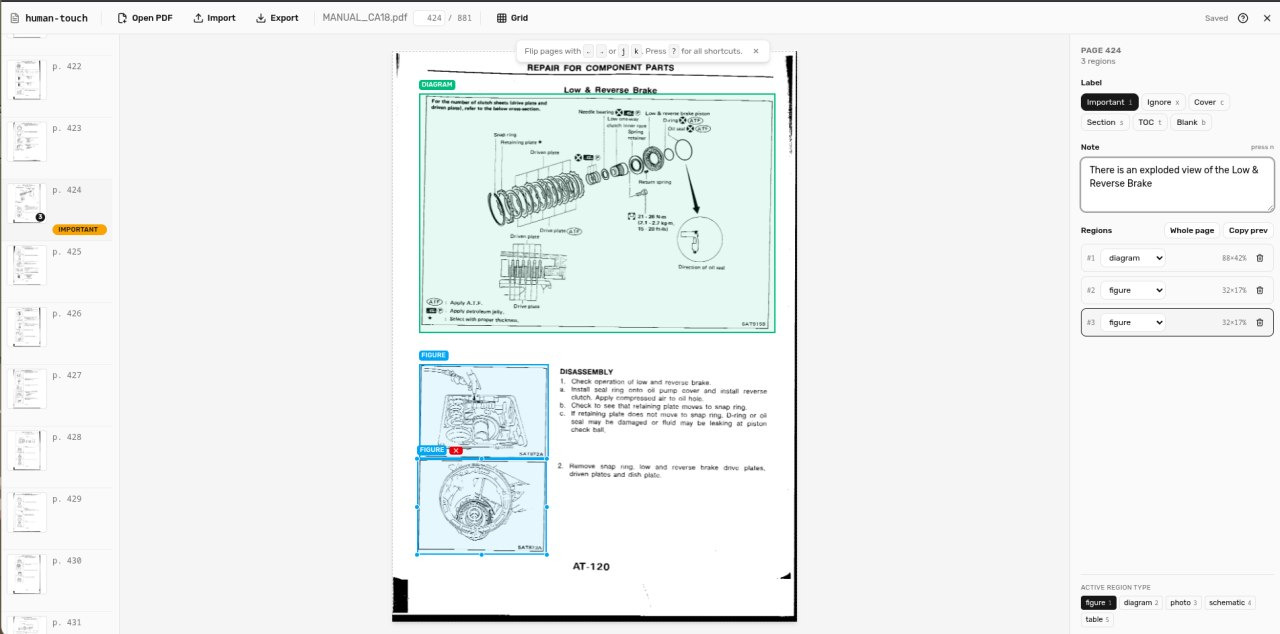
human-touch is a small Vite + React SPA I built specifically for the annotation half of the loop.
It loads a PDF entirely client-side via pdfjs-dist, lets me label each page (important / ignore / cover / section_divider / index_toc / blank), draw bounding boxes around figures with a label (figure / diagram / photo / schematic / table), and leave free-text notes that flow through to the extractor. Everything is auto-saved to OPFS (the browser’s Origin Private File System), fingerprinted by the PDF’s hash, so my annotations survive reloads without ever leaving the laptop. There’s an export button that spits out a JSON sidecar; that sidecar is what the extractor reads alongside the raw PDF.
It’s the unglamorous part of the project, but it’s the part that makes the difference between “Claude got it 90% right” and “Claude got it 99% right where it counts.” For a workshop manual that someone’s going to consult while their hands are covered in oil, that last 9% matters.
The frontend
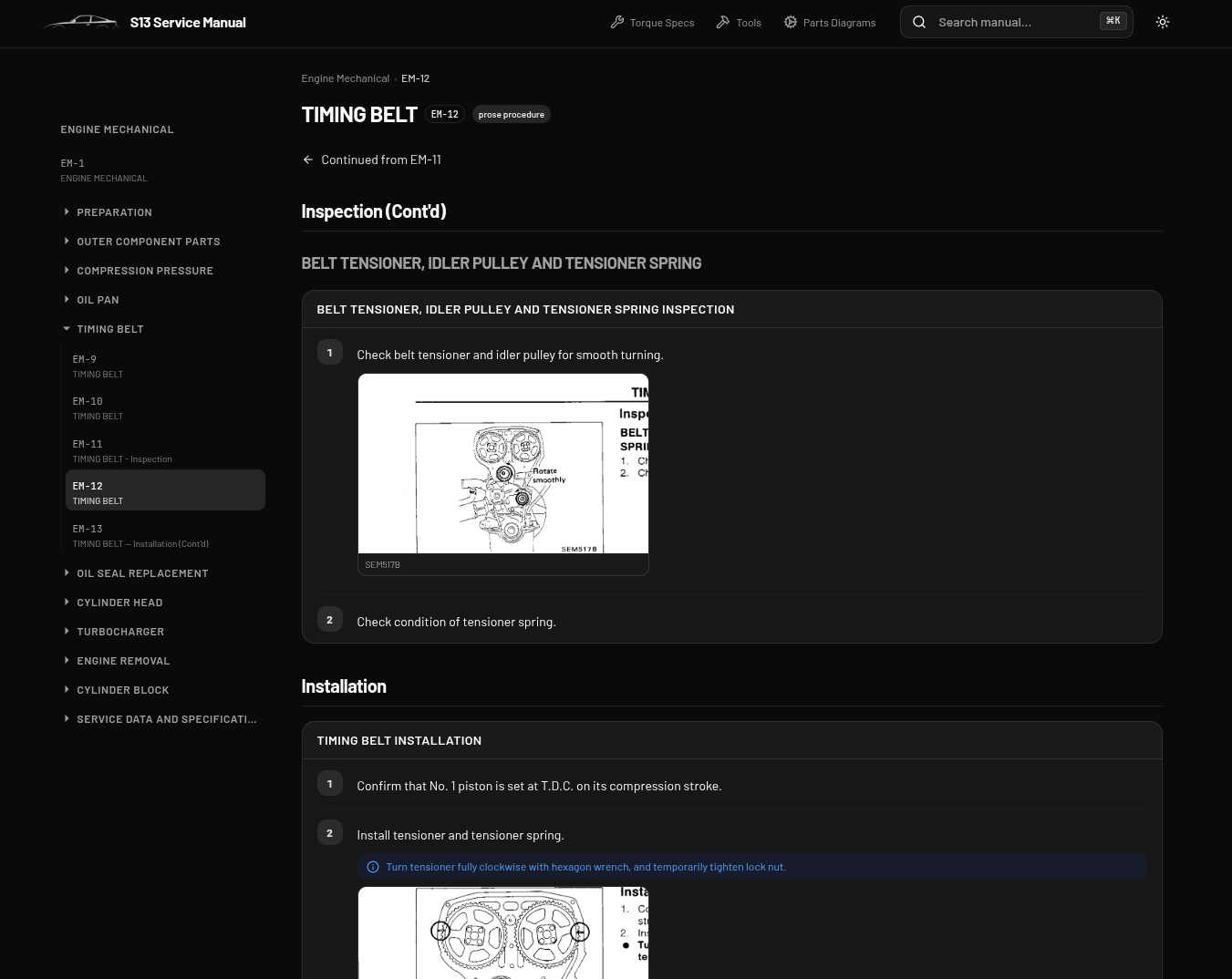
The viewer side is a single Next.js 16 app, statically exported and served from Cloudflare. The clever bit is that the same codebase serves N car models. Each model lives in its own data repo (s13-data, k11-data) attached as a submodule, holding manual.json (site config, sections), one JSON per page, and the figure images. Adding a new model is “create a new data repo, point at it, deploy”. No per-model code.
Every extracted page is a list of typed blocks, and every block type has its own React renderer: procedure, specs, flowchart (rendered with Mermaid), table, component_location, parts_diagram, wiring_schematic, diagnostic_code, plus the boring heading and prose ones.
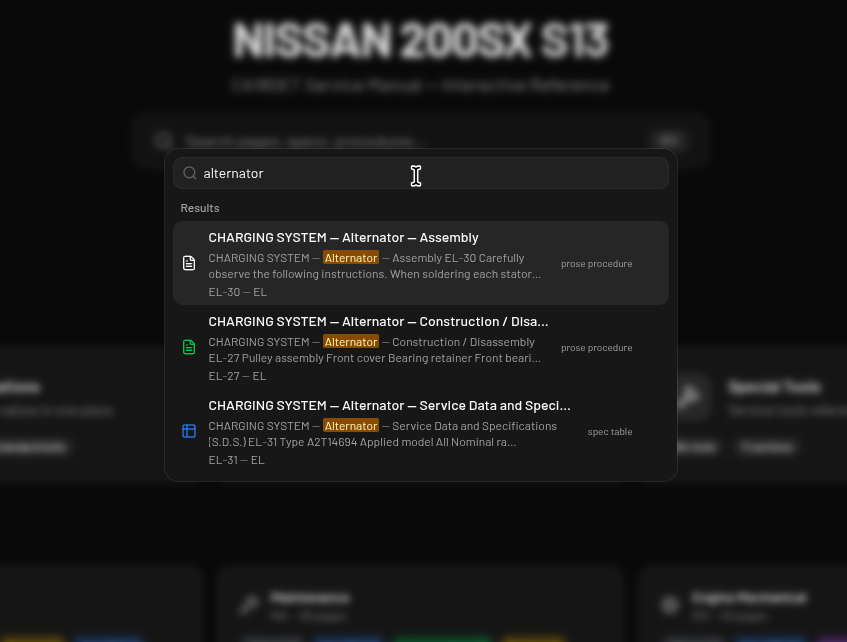
Search is fully client-side via MiniSearch, with the index pre-built at compile time and shipped as a static JSON file. Hit Cmd+K and you’re typing. No server, no API call, no cold start.
Numbers so far
- S13: 526 pages extracted, ~1,400 figures
- K11: 625 pages extracted, ~1,400 figures
- Total: north of 1,150 pages and 2,800 images of structured workshop content
Two manuals, one codebase, zero servers.
What’s next
More models are the obvious next step. The sucatisse name was always meant to cover more than one car. Mobile polish is on the list (the use case is genuinely “phone propped on the wing while elbow-deep in the engine bay”). And I’d like to clean up human-touch enough to share with other people restoring old machines, because I doubt I’m the only one whose service manual is a 30-year-old PDF that was never meant to be read on a screen.
If you’re tinkering with something old and badly documented, ping me. There’s probably a manual for it that deserves the same treatment.